O que é Robots.txt?
Robots.txt é um arquivo em forma de texto que instrui os rastreadores de bots a indexar ou não indexar certas páginas. Ele também é conhecido como o porteiro de todo o seu site. O primeiro objetivo dos rastreadores de bots é encontrar e ler o arquivo robots.txt, antes de acessar o seu sitemap ou quaisquer páginas ou pastas.
Com robots.txt, você pode mais especificamente:
- Regule como os bots de motores de busca rastreiam seu site
- Forneça certo acesso
- Ajude os spiders de motores de busca a indexar o conteúdo da página
- Mostre como servir conteúdo aos usuários
Robots.txt é uma parte do Protocolo de Exclusão de Robôs (R.E.P), composto por diretivas de nível de site/página/URL. Embora os bots de motores de busca ainda possam rastrear todo o seu site, cabe a você ajudá-los a decidir se certas páginas valem o tempo e o esforço.
Por que você precisa de Robots.txt
Seu site não precisa de um arquivo robots.txt para funcionar corretamente. Os principais motivos pelos quais você precisa de um arquivo robots.txt é para que, quando os bots rastrearem sua página, eles peçam permissão para rastrear, para que possam tentar recuperar informações sobre a página para indexar. Além disso, um site sem um arquivo robots.txt está basicamente convidando os bots rastreadores a indexar o site como acharem adequado. É importante entender que os bots ainda rastrearão seu site sem o arquivo robots.txt.
A localização do seu arquivo robots.txt também é importante porque todos os bots procurarão por www.123.com/robots.txt. Se eles não encontrarem nada lá, assumirão que o site não possui um arquivo robots.txt e indexarão tudo. O arquivo deve ser um arquivo de texto ASCII ou UTF-8. Também é importante notar que as regras diferenciam maiúsculas de minúsculas.
Aqui estão algumas coisas que o robots.txt fará e não fará:
- O arquivo é capaz de controlar o acesso de rastreadores a certas áreas do seu site. Você precisa ter muito cuidado ao configurar o robots.txt, pois é possível bloquear todo o site para que não seja indexado.
- Ele impede que conteúdo duplicado seja indexado e apareça nos resultados de motores de busca.
- O arquivo especifica o atraso de rastreamento para evitar que os servidores fiquem sobrecarregados quando os rastreadores estiverem carregando várias peças de conteúdo ao mesmo tempo.
Aqui estão alguns Googlebots que podem rastrear o seu site de vez em quando:
| Web Crawler | Cadeia de Caracteres do User-Agent |
| Notícias do Googlebot | Googlebot-News |
| Googlebot Imagens | Googlebot-Image/1.0 |
| Googlebot Vídeo | Googlebot-Video/1.0 |
| Google Mobile (telefone com recursos) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatível; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Smartphone Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatível; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (compatível; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (qualidade da página de destino PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (busca recursos para dispositivos móveis) | AdsBot-Google-Mobile-Apps |
Você pode encontrar uma lista de bots adicionais aqui.
- Os arquivos ajudam na especificação da localização dos sitemaps.
- Também impede que os bots dos motores de busca indexem vários arquivos no site, como imagens e PDFs.
Quando um bot deseja visitar o seu site (por exemplo, www.123.com), ele inicialmente verifica www.123.com/robots.txt e encontra:
User-agent: *
Disallow: /
Este exemplo instrui todos os (User-agents*) bots de motores de busca a não indexar (Disallow: /) o site.
Se você removeu a barra à frente de Disallow, como no exemplo abaixo,
User-agent: *
Disallow:
os bots seriam capazes de rastrear e indexar tudo no site. É por isso que é importante entender a sintaxe de robots.txt.
Entendendo a sintaxe do robots.txt
A sintaxe do robots.txt pode ser considerada como a "linguagem" dos arquivos robots.txt. Existem 5 termos comuns que você provavelmente encontrará em um arquivo robots.txt. Eles são:
- User-agent: O rastreador web específico ao qual você está dando instruções de rastreamento (geralmente um mecanismo de busca). Uma lista da maioria dos user agents pode ser encontrada aqui.
- Disallow: O comando usado para dizer a um agente do usuário para não rastrear uma URL específica. Apenas uma linha "Disallow:" é permitida para cada URL.
- Allow (Apenas aplicável para Googlebot):O comando indica ao Googlebot que ele pode acessar uma página ou subpasta mesmo que sua página ou subpasta pai esteja proibida.
- Crawl-delay: O número de milissegundos que um rastreador deve esperar antes de carregar e rastrear o conteúdo da página. Note que o Googlebot não reconhece este comando, mas a taxa de rastreamento pode ser definida no Google Search Console.
- Mapa do site: Usado para indicar a localização de qualquer mapa do site em XML associado a um URL. Observe que este comando é suportado apenas pelo Google, Ask, Bing e Yahoo.
Resultados das instruções Robots.txt
Você espera três resultados quando emite instruções no robots.txt:
- Permissão total
- Negação total
- Permissão condicional
Vamos investigar cada um abaixo.
Permissão total
Este resultado significa que todo o conteúdo do seu site pode ser rastreado. Arquivos robots.txt são destinados a bloquear o rastreamento por bots de motores de busca, então este comando pode ser muito importante.
Esse resultado pode significar que você não tem um arquivo robots.txt no seu site de forma alguma. Mesmo que você não o tenha, os bots dos motores de busca ainda o procurarão no seu site. Se eles não o encontrarem, então eles rastrearão todas as partes do seu site.
A outra opção sob esse resultado é criar um arquivo robots.txt, mas mantê-lo vazio. Quando o spider vier rastrear, ele identificará e até lerá o arquivo robots.txt. Como não encontrará nada lá, ele prosseguirá para rastrear o restante do site.
Se você tem um arquivo robots.txt e possui as seguintes duas linhas nele,
User-agent:*
Disallow:
o spider do motor de busca vai rastrear o seu site, identificar o arquivo robots.txt e lê-lo. Ele chegará à linha dois e então prosseguirá para rastrear o resto do site.
Proibição total
Aqui, nenhum conteúdo será rastreado e indexado. Este comando é emitido por esta linha:
User-agent:*
Disallow:/
Quando falamos sobre nenhum conteúdo, queremos dizer que nada do site (conteúdo, páginas, etc.) pode ser rastreado. Isso nunca é uma boa ideia.
Permissão Condicional
Isso significa que apenas determinados conteúdos no site podem ser rastreados.
Uma permissão condicional tem este formato:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Permitir:/
Você pode encontrar a sintaxe completa do robots.txt aqui.
Note que páginas bloqueadas ainda podem ser indexadas mesmo que você tenha desautorizado a URL conforme mostrado na imagem abaixo:
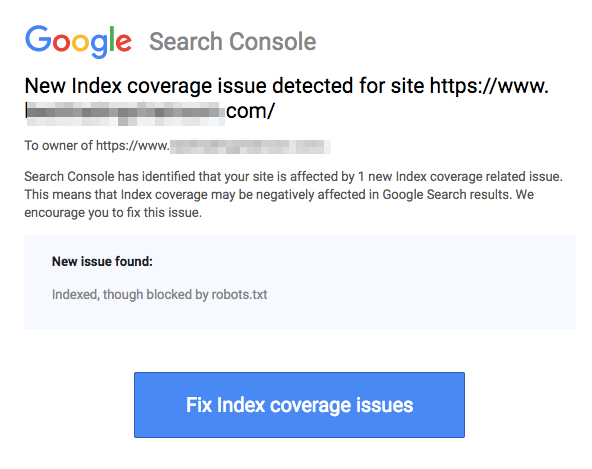
Você pode receber um e-mail dos motores de busca informando que seu URL foi indexado, como na captura de tela acima. Se o seu URL proibido estiver vinculado a outros sites, como texto âncora em links, ele será indexado. A solução para isso é 1) proteger seus arquivos com senha no seu servidor, 2) usar a meta tag noindex, ou 3) remover a página inteiramente.
Um robô ainda pode escanear e ignorar meu arquivo robots.txt?
Sim. é possível que um robô ignore o robots.txt. Isso ocorre porque o Google usa outros fatores, como informações externas e links de entrada, para determinar se uma página deve ser indexada ou não. Se você não quer que uma página seja indexada de forma alguma, você deve utilizar a meta tag de robôs noindex. Outra opção seria usar o cabeçalho HTTP X-Robots-Tag.
Posso bloquear apenas os robôs ruins?
É possível bloquear robôs mal-intencionados em teoria, mas pode ser difícil fazer isso na prática. Vamos olhar algumas maneiras de fazer isso:
- Você pode bloquear um robô ruim excluindo-o. No entanto, você precisa saber o nome pelo qual o robô específico faz a varredura no campo User-Agent. Então, você precisa adicionar uma seção no seu arquivo robots.txt que exclua o robô ruim.
- Configuração do servidor. Isso só funcionaria se a operação do robô mal-intencionado fosse de um único endereço IP. A configuração do servidor ou um firewall de rede bloqueará o robô mal-intencionado de acessar o seu servidor web.
- Usando configurações avançadas de regras de firewall. Estas irão bloquear automaticamente o acesso aos vários endereços IP onde cópias do robô malicioso existem. Um bom exemplo de bots operando em vários endereços IP é no caso de PCs sequestrados que podem até fazer parte de uma Botnet maior (saiba mais sobre Botnet aqui).
Se o robô mal-intencionado opera a partir de um único endereço IP, você pode bloquear o acesso dele ao seu servidor web através da configuração do servidor ou com um firewall de rede.
Se cópias do robô operarem em uma série de diferentes endereços IP, então se torna mais difícil bloqueá-los. A melhor opção neste caso é usar configurações avançadas de regras de firewall que bloqueiam automaticamente o acesso a endereços IP que fazem muitas conexões; infelizmente, isso pode afetar o acesso de bons robôs também.
Quais são algumas das melhores práticas de SEO ao usar o robots.txt?
Neste ponto, você pode estar se perguntando como navegar por essas águas muito complicadas do robots.txt. Vamos olhar isso com mais detalhes:
- Certifique-se de que você não está bloqueando nenhum conteúdo ou seções do seu site que você deseja que sejam rastreados.
- Use um mecanismo de bloqueio diferente de robots.txt se você deseja que a autoridade de link seja passada de uma página com robots.txt (o que significa que ela está praticamente bloqueada) para o destino do link.
- Não use o robots.txt para impedir que dados sensíveis, como informações privadas de usuários, apareçam nos resultados de motores de busca. Fazer isso pode permitir que outras páginas criem links para páginas que contêm informações privadas de usuários, o que pode fazer com que a página seja indexada. Neste caso, o robots.txt foi contornado. Outras opções que você pode explorar aqui são proteção por senha ou a diretiva meta noindex.
- Não há necessidade de especificar diretivas para cada um dos rastreadores de um mecanismo de busca, pois a maioria dos agentes de usuário, se pertencerem ao mesmo mecanismo de busca, segue as mesmas regras. O Google usa o Googlebot para mecanismos de busca e o Googlebot Image para buscas de imagens. A única vantagem de saber como especificar cada rastreador é que você é capaz de ajustar exatamente como o conteúdo do seu site é rastreado.
- Se você alterou o arquivo robots.txt e deseja que o Google o atualize mais rapidamente, envie-o diretamente para o Google. Para instruções de como fazer isso, clique aqui. É importante notar que os motores de busca armazenam em cache o conteúdo do robots.txt e atualizam o conteúdo em cache pelo menos uma vez por dia.
Diretrizes básicas do robots.txt
Agora que você tem um entendimento básico de SEO em relação ao robots.txt, quais coisas você deve ter em mente ao usar o robots.txt? Nesta seção, vamos olhar algumas diretrizes a seguir ao usar o robots.txt, embora seja importante ler a sintaxe completa.
Formato e localização
O editor de texto que você escolher para usar na criação de um arquivo robots.txt precisa ser capaz de criar arquivos de texto padrão ASCII ou UTF-8. Usar um processador de texto não é uma boa ideia, pois alguns caracteres que podem afetar a rastreabilidade podem ser adicionados.
Enquanto quase qualquer editor de texto pode ser usado para criar seu arquivo robots.txt, esta ferramenta é altamente recomendada, pois permite testes contra o seu site.
Aqui estão mais orientações sobre formato e localização:
- Você deve nomear o arquivo que você criar como “robots.txt” porque o arquivo é sensível a maiúsculas e minúsculas. Não são utilizados caracteres em caixa alta.
- Você só pode ter um arquivo robots.txt em todo o site.
- O arquivo robots.txt está localizado em apenas um lugar: a raiz do host do site ao qual ele é aplicável. Observe que ele não pode ser colocado em um subdiretório. Se o seu site éhttp://www.123.com/, então o local do robots.txt é http://www.123.com/robots.txt, não http://www.123.com/pages/robots.txtObserve que o arquivo robots.txt pode ser aplicado a subdomínios (http://website.123.com/robots.txt) e até portas não-padrão, como http://www.123.com: 8181/robots.txtPor favor, forneça o texto que você gostaria que fosse traduzido para o português (Brasil).
Como mencionado anteriormente, o robots.txt não é a melhor maneira de impedir que informações pessoais sensíveis sejam indexadas. Isso é uma preocupação válida, especialmente agora com o GDPR recentemente implementado. A privacidade dos dados não deve ser comprometida. Ponto final.
Como você garante então que o robots.txt não exiba dados sensíveis nos resultados de pesquisa?
Usar um subdiretório separado que seja "não listável" na web impedirá a distribuição de material sensível. Você pode garantir que ele seja "não listável" usando a configuração do servidor. Simplesmente armazene todos os arquivos que você não quer que o robots.txt visite e indexe neste subdiretório.
Listar páginas ou diretórios no arquivo robots.txt resulta em acesso não intencional?
Como mencionado anteriormente, colocar todos os arquivos que você não deseja que sejam indexados em um subdiretório separado e, em seguida, torná-lo não listável por meio de configurações do servidor deve garantir que eles não apareçam nos resultados de pesquisa. A única listagem que você fará então no arquivo robots.txt é o nome do diretório. A única maneira de acessar esses arquivos é por meio de um link direto para um dos arquivos.
Aqui está um exemplo:
Em vez de
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Use
User-Agent:*
Disallow:/norobots/
Você então precisa criar um diretório "norobots", que inclui foo.html e bar.html. Observe que as configurações do seu servidor precisam estar claras sobre não gerar uma listagem de diretório para o diretório "norobots".
Este pode não ser um método muito seguro porque a pessoa ou bot atacando seu site ainda pode ver que você tem um diretório “norobots” mesmo que eles não possam ser capazes de visualizar os arquivos dentro do diretório. No entanto, alguém poderia publicar um link para esses arquivos em seu site ou, pior ainda, o link pode aparecer em um arquivo de log que é acessível ao público (por exemplo, um log de servidor web como um referenciador). Uma má configuração do servidor também é possível, resultando em uma listagem de diretório.
O que isso significa? O Robots.txt não pode ajudá-lo a controlar o acesso pelo simples motivo de que ele não é destinado a isso. Um bom exemplo é uma "placa de proibido entrar". Há pessoas que ainda violarão a instrução.
Se houver arquivos que você deseja que sejam acessados apenas por pessoas autorizadas, as configurações do servidor ajudarão com a autenticação. Se você usa um CMS (Sistema de Gerenciamento de Conteúdo), você tem controles de acesso em páginas individuais e coleção de recursos.
Você pode otimizar o robots.txt para SEO?
Com certeza. O melhor guia sobre como otimizar o robots.txt é o conteúdo do site. Um lembrete rápido: Robots.txt nunca deve ser usado para bloquear páginas de serem rastreadas pelos bots de motores de busca. Use-o apenas para bloquear as seções do seu site que não são acessíveis ao público, por exemplo, páginas de login como wp-admin.
Esta é a linha de desalinhamento para a página de login do Neil Patel em um de seus sites:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Você pode usar esta linha de disallow para impedir que seu login seja indexado.
Se houver algumas páginas específicas que você não deseja que sejam indexadas, use o mesmo comando acima. Um exemplo:
User-agent:*
Disallow:/page/
Especifique a página que você não quer que seja indexada após a barra e feche com outra barra. Por exemplo:
User-agent:*
Disallow:/page/thank-you/
Quais são algumas das páginas que você pode querer excluir da indexação?
- Conteúdo duplicado que é intencional. O que isso significa? Às vezes, você cria intencionalmente conteúdo duplicado para alcançar um propósito específico. Um bom exemplo é uma versão da página da web otimizada para impressão. Você pode usar robots.txt para bloquear a indexação da versão otimizada para impressão do conteúdo idêntico.
- Páginas de agradecimento. A razão pela qual você deseja bloquear esta página de ser indexada é simples: Ela deve ser o último passo no funil de vendas. Quando seus visitantes chegarem a esta página, eles já deveriam ter passado por todo o funil de vendas. Se esta página for indexada, significa que você pode perder leads ou que receberá leads falsos.
O comando para bloquear tal página é:
Disallow:/thank-you/
Noindex e NoFollow
Como temos dito ao longo deste artigo, usar o robots.txt não é uma garantia de 100% de que sua página não será indexada. Vamos olhar para duas maneiras de garantir que sua página bloqueada realmente não seja indexada.
A diretiva noindex
Isso funciona em conjunto com o comando disallow. Use ambos na sua diretiva, como em:
Disallow:/thank-you/
A diretiva nofollow
Isso funciona para instruir especificamente os bots do Google a não rastrear os links em uma página. Isso não faz parte do arquivo robots.txt. Para usar o comando nofollow para bloquear páginas de serem rastreadas e indexadas, você precisa encontrar o código-fonte da página específica que você não quer indexada.
Cole isso entre as tags de abertura e fechamento head:
<meta name = “robots” content=”nofollow”>
Você pode usar tanto “nofollow” quanto “noindex” simultaneamente. Use esta linha de código:
<meta name = “robots” content=”noindex,nofollow”>
Gerando robots.txt
Se você acha difícil escrever robots.txt usando todos os formatos e sintaxes necessários que você precisa entender e seguir, você pode usar ferramentas que simplificam o processo. Um bom exemplo é o nosso gerador de robots.txt gratuito.
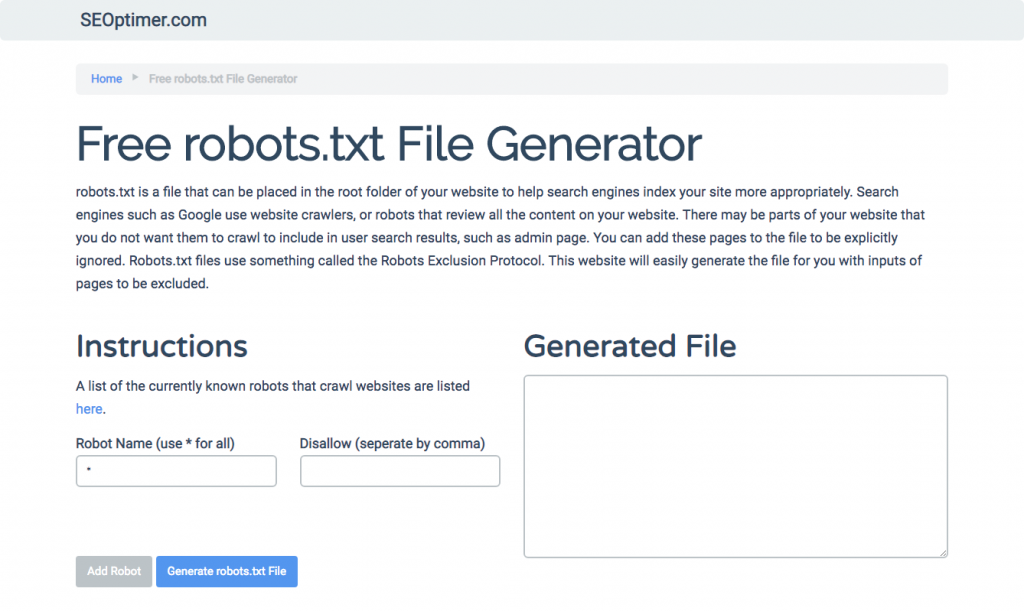
Esta ferramenta permite que você escolha o tipo de resultado que você precisa em seu site e o arquivo ou diretórios que você deseja adicionar. Você pode até testar seu arquivo e ver como sua concorrência está se saindo.
Testando o seu arquivo robots.txt
Você precisa testar seu arquivo robots.txt para garantir que ele está funcionando conforme o esperado.
Use o testador de robots.txt do Google.
Para fazer isso, faça login na sua conta de Webmaster.
- Em seguida, selecione sua propriedade. Neste caso, é o seu site.
- Clique em "crawl" na barra lateral esquerda.
- Clique em "robots.txt tester".
- Substitua qualquer código existente pelo seu novo arquivo robots.txt.
- Clique em "testar".
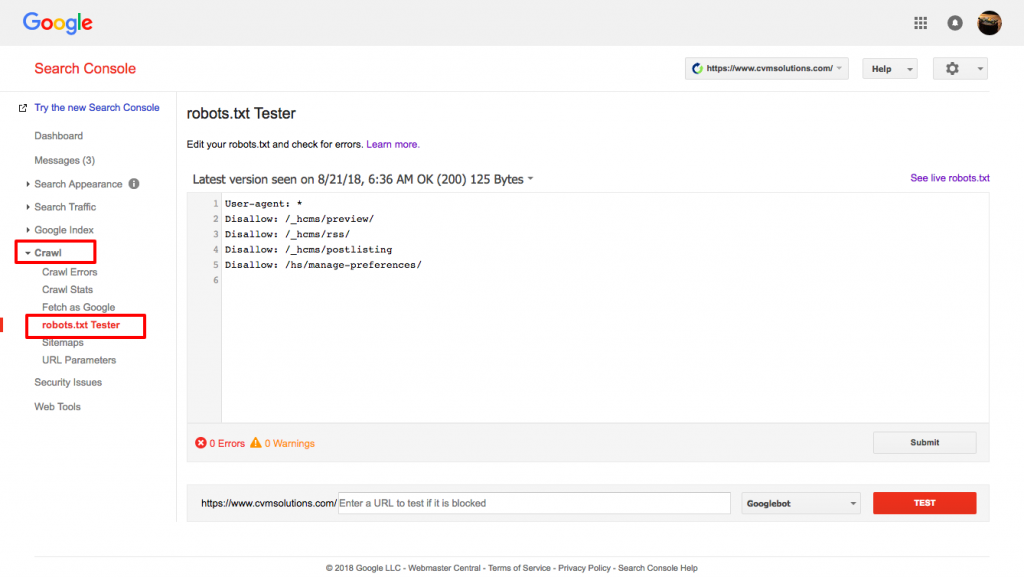
Você deve ser capaz de ver uma caixa de texto "permitido" se o arquivo for válido. Para mais informações, confira este guia detalhado sobre o testador de robots.txt do Google.
Se o seu arquivo é válido, agora é hora de fazer o upload dele para o seu diretório raiz ou salvá-lo se lá houver outro arquivo robots.txt.
Como adicionar robots.txt ao seu site WordPress
Para adicionar um arquivo robots.txt ao seu arquivo WordPress, vamos abordar opções de plugin e FTP.
Para a opção de plugin, você pode usar um plugin como All in One SEO Pack
Para fazer isso, faça login no seu painel do WordPress
Role a página para baixo até chegar em "plugins"
Clique em "adicionar novo"
Vá até "search plugins"
Digite “All in One SEO Pack”
Instale e ative
Na seção Configurações Gerais do plugin All in One SEO, você pode configurar as regras de noindex e nofollow para serem incluídas no seu arquivo robots.txt.
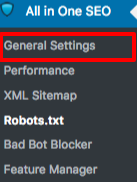
Você pode especificar quais URLs devem ser NOINDEX, NOFOLLOW. Deixar estas opções desmarcadas por padrão será indexado:
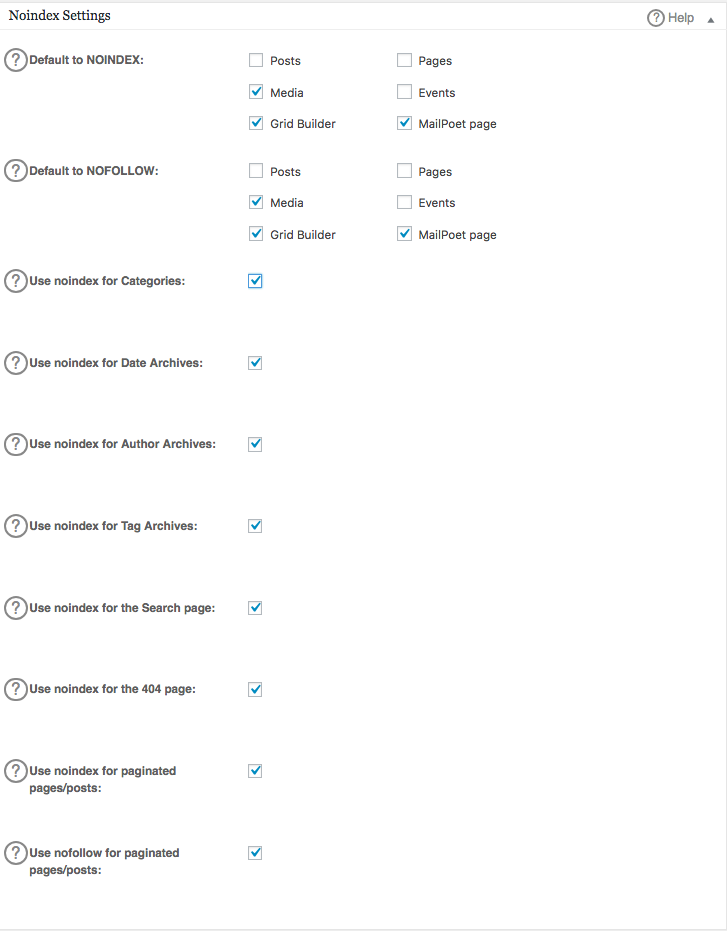
Para criar regras avançadas no seu arquivo robots.txt, clique no gerenciador de recursos, depois no botão ativar logo abaixo de robots.txt.
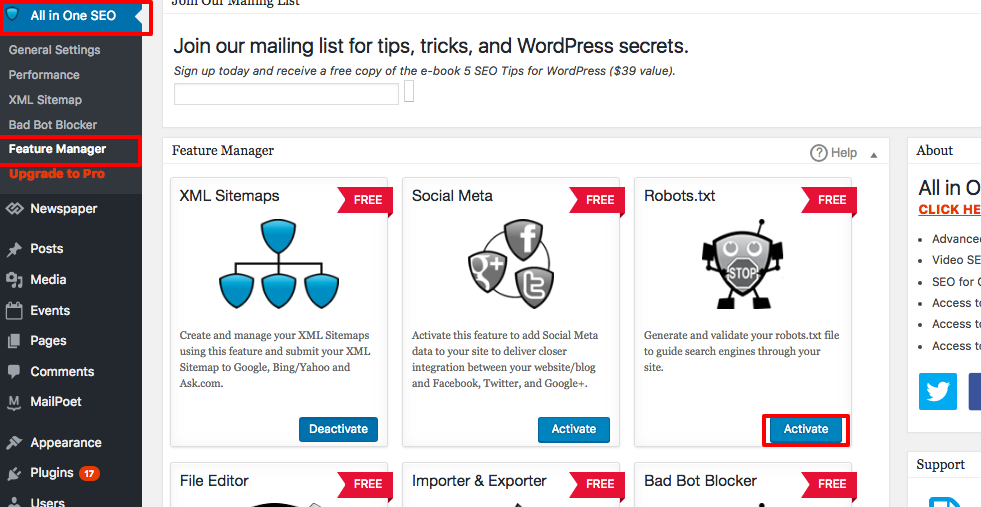
Robots.txt agora aparece logo abaixo do gerenciador de recursos. Clique nele. Você verá uma seção chamada "criar um arquivo robots.txt".
Existe uma seção de construtor de regras que permite escolher e preencher as regras que você deseja para o seu site, dependendo do que você quer ou não quer indexado.
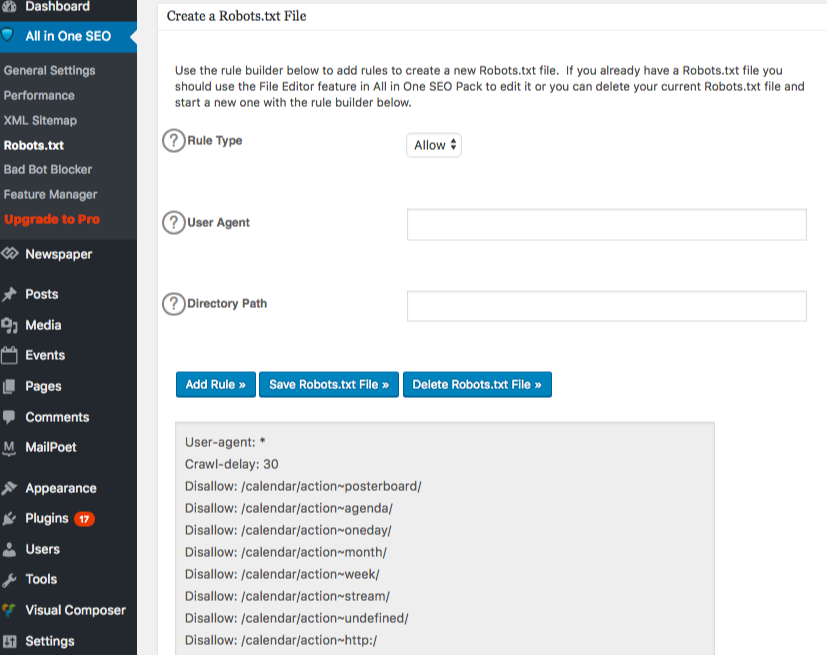
Uma vez que você terminar de criar a regra, clique em "adicionar regra".
A regra será então listada sob a pasta robots.txt criada.
Você verá uma mensagem indicando que as “All in One Options” foram atualizadas.
Outro método que você pode usar é fazer o upload do seu arquivo robots.txt diretamente para o seu cliente de FTP (Protocolo de Transferência de Arquivos) como o FileZilla.
Uma vez que você tenha gerado seu arquivo robots.txt, você pode localizá-lo e substituí-lo. Seu arquivo robots.txt estará localizado em: “/applications/[NOME DA PASTA]/public_html.”
Como editar o arquivo robots.txt no seu Wix
O Wix gera um arquivo robots.txt para sites que utilizam a plataforma de construção de sites. Para visualizá-lo, adicione “/robots.txt” ao seu domínio. Os arquivos adicionados ao robots.txt têm a ver com a estrutura dos sites Wix, por exemplo, links noflashhtml, que não contribuem para o valor de SEO do seu site impulsionado pelo Wix.
Você não pode editar seu arquivo robots.txt se o seu site for hospedado pelo Wix. Você só pode usar outras opções como adicionar uma "tag noindex" às páginas que você não quer que sejam indexadas.
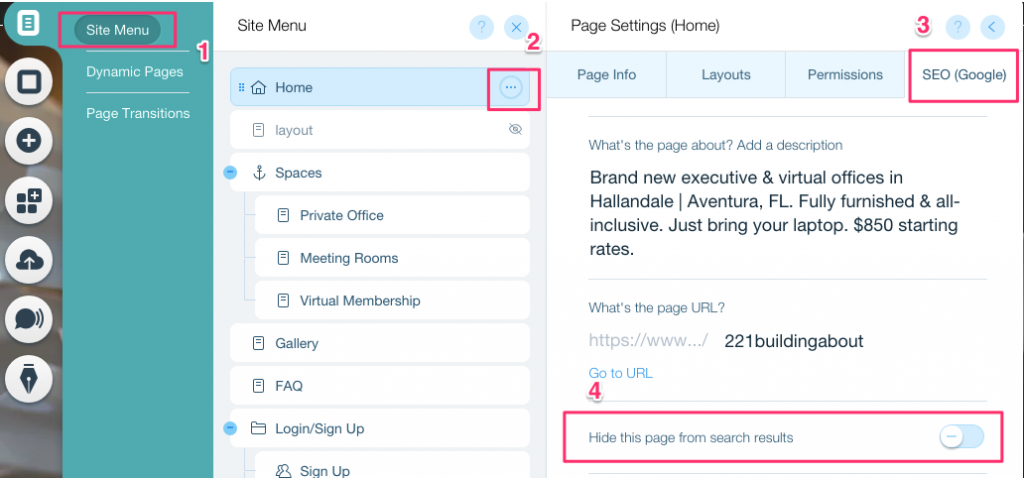
Para criar uma tag noindex para uma página específica:
- Clique em Menu do Site
- Clique na opção Configurações para aquela página específica
- Selecione a tag SEO (Google)
- Ative Ocultar esta página dos resultados de pesquisa
Como editar o arquivo robots.txt no seu Shopify
Assim como no Wix, o Shopify adiciona automaticamente um arquivo robots.txt ineditável ao seu site. Se você não quer que algumas páginas sejam indexadas, você precisa adicionar a "tag noindex" ou despublicar a página. Você também pode adicionar meta tags na seção de cabeçalho das páginas que você não quer que sejam indexadas. Isso é o que você deve adicionar ao seu cabeçalho:
<meta name= “robots” content = “noindex”>
A Shopify criou um guia detalhado sobre como ocultar páginas dos motores de busca que você pode seguir.
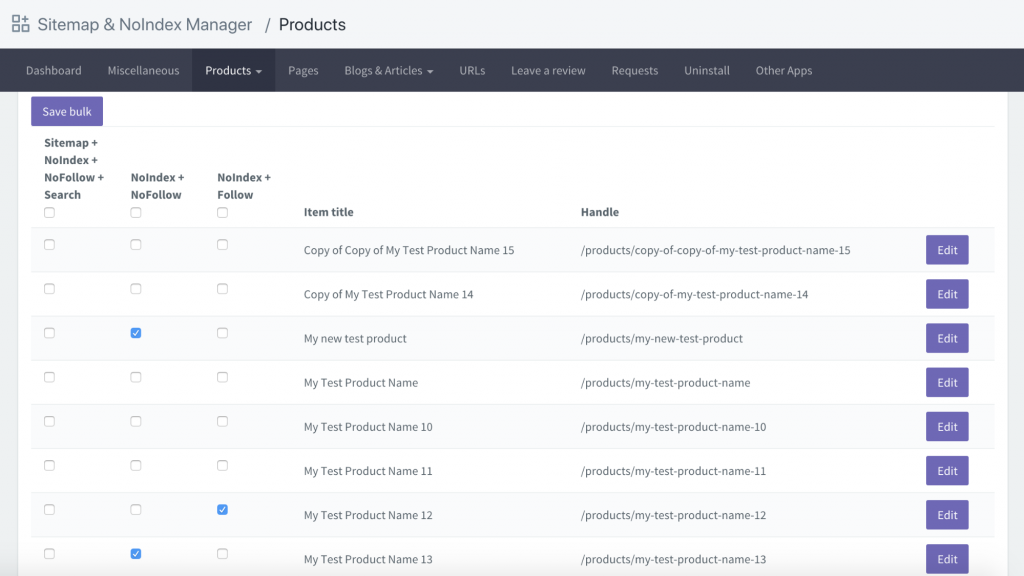
Outra opção é baixar um aplicativo chamado Sitemap & NoIndex Manager da Orbis Labs. Você pode simplesmente marcar as opções de noindex ou nofollow para cada página no seu site Shopify: